
(This is a follow up to part 1 which you can see here. Posted by Patrick Lee on 15 August 2017 at a different location, but migrated here on 05 Feb 2018).
Proposed First Draft
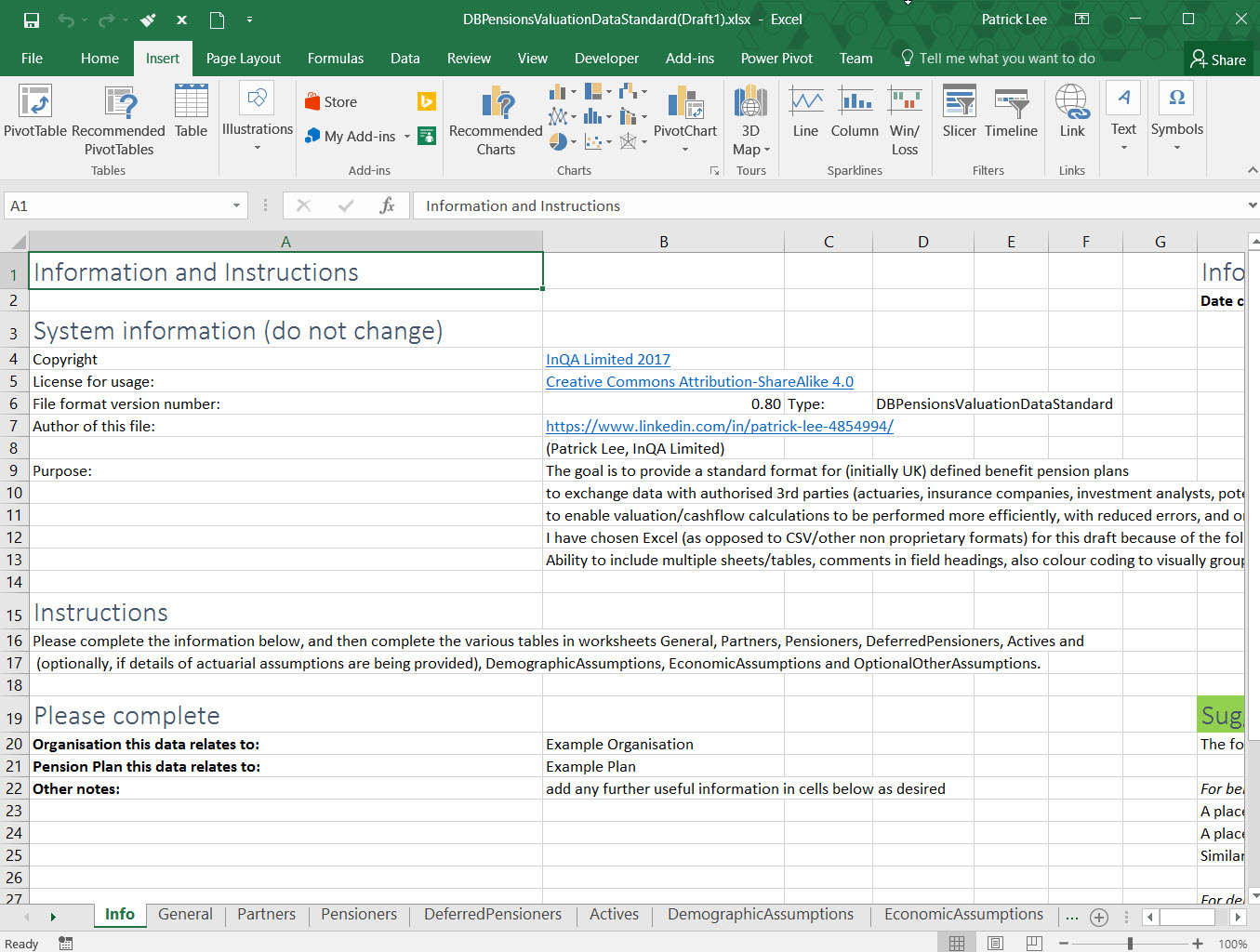
I’ve now completed a first draft of a proposed standard, as a Microsoft Excel file (118kB, so quite small). You can download it here. Comments/criticisms most welcome. Let’s make this happen!
Why Microsoft Excel?
I’ve chosen to put it in an Excel file (as opposed to CSV or other non proprietary formats) for the moment because Excel offers the following advantages:
- we can put several different worksheets/tables in a single file
- field headings can have explanatory comments
- I’ve using colour coding to visually group similar fields.
The goal
The goal is to provide a standard format for (initially UK) defined benefit pension plans to exchange data with authorised 3rd parties (actuaries, insurance companies, investment analysts, potential purchasers etc) to enable valuation/cashflow calculations to be performed more efficiently, with reduced errors, and on a more comparable basis.
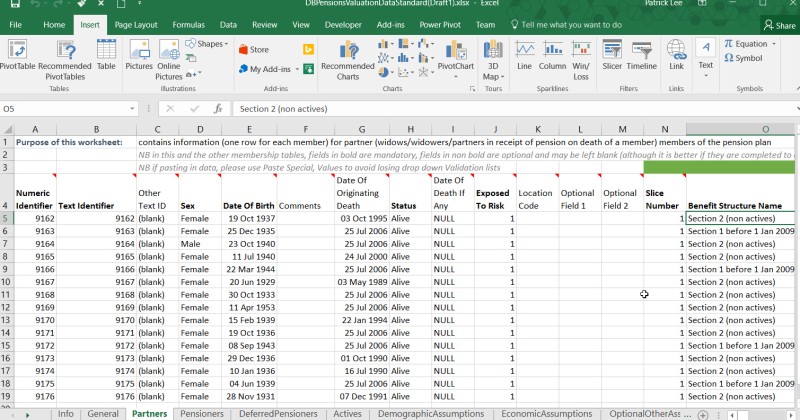
Ideally, start with the Info sheet, then the Partners (widows/widowers) sheet is probably the easiest to understand. The Benefit Structure Name fields (for up to 10 slices of benefits – see * below as to why 10 and how more could be allowed for if necessary) need to match values set in the Benefit Structures table in the General worksheet.
Completing the Minimum (benefits and membership data)
The minimum amount of data that needs to be completed is that in the General, Partners, Pensioners, Deferred Pensioners and Actives worksheets (as well as 2 or more fields in the “Please Complete” section of the Info worksheet), which is enough (although see H19 in worksheet Info) to provide membership and benefits data in order to value the pension promises made or project their cashflows.

Full data: specifying the assumptions to use for calculation too
If it is desired to go further and to specify the demographic and economic assumptions to be used to perform the calculations, then the DemographicAssumptions, EconomicAssumptions and OptionalOtherAssumptions worksheets should be completed. In particular, this should go a long way to narrowing down artificial differences in calculation results which can arise from hidden secondary assumptions (see How corporate pension liabilities could vary by 10% or more, even on an agreed set of assumptions).
Suggested improvements
Please see the “Suggested Improvements to the Draft” section (starting in cell H19 in worksheet Info) for things that I would like to add, but have not yet (partly because of time but mainly because I would like to get feedback from others first).
Notes
Note *: the draft currently allows up to 10 benefit slices for members because this should be sufficient in the vast majority of cases. If a variable number (possibly higher) is needed, the format could be altered to put the benefit slice information into separate tables, where each row represents one slice for a particular member, identified via the first field being that members unique Numeric Identifier. (Similarly for other variable length items, such as part time history and salary history for active members). (That more flexible approach is the one we take in our Concerto valuation/cashflow software, but at the moment I feel that the current draft should cover the vast majority of pension plans).
P.S. I’m also aware that some UK (current or former) public sector pension plans have more complex benefits that would require some additional fields (mainly for active members), but I would like to seek consensus/feedback on the developing a standard for majority of UK pensions plans, which are probably the private sector ones.
